-
提出了一个会思考的AI框架,由一个以预测为目标的基于RNN的世界模型M,和一个以最大化外部和内部reward为目标的基于强化学习的控制模型C组成。
Predictive RNN world model + RL controller
-
回顾了很多相关工作(主要是自己的),主要包括RL+RNN,SL&UL,LSTM&CTC,Hierarchical & multitask RL
理论基础:
-
Algorithmic Information Theory 用看似高深的算法信息论提出了一个transfer learning的指导思想,结论是如果有两个程序p和q,在已知p的情况下,求K(q|p)要比直接求q来得简单。
这个结论成立应该有一些assumption,比如说p和q的互相关性要大(不知道为什么论文里说要小),比如说p的计算复杂度不高等等。
这篇文章处处使用了这个结论,但是没有对这些假设、推导过程作深入探讨。
架构和算法:
系统主要有两个部分组成M和C。
-
M的主要目标是compress and save。
输入C(t)、M(t)、sense(t),输出sense_pred(t+1)。
对应于save,M要最小化predictive error;对应于compress,M要最小化使用的计算资源,例如尽量减少non-zero的weights。
-
C的主要目标是最大化external和intrinsic rewards。
输入C(t)、M(t)、sense(t),输出out(t)。
Reward分为external和intrinsic两种,可以对应于YY总结的生理需求的reward和美学reward。生理需求reward包括吃喝、社交、疼痛、财富等等;美学reward也就是Schmidhuber总结的对world model的提升。
C和M之间可以交互,M是一个复杂庞大的模块,通过利用M的信息,C可以只用很简单的架构。
训练时交替训练M和C,白天和环境交互获得新的数据,训练C,fix M的参数;晚上训练M。
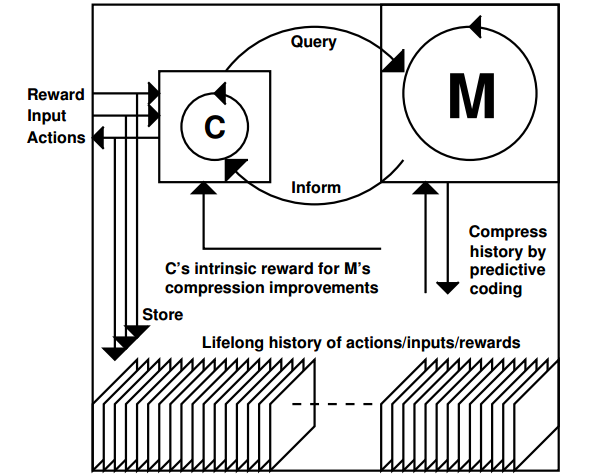
这个系统的要点:
- M要努力记录下agent的所有输入输出,并且要用尽可能少的资源做到这一点。M使用SL,loss由两部分组成:predict错误和M的非零weights数。
- C有external和intrinsic两种rewards。
- C要以一种很聪明的方式与M交互,C和M组成一个大的RNN,使得C能够以任意可计算方式利用M(C’s programs may query, edit or invoke subprograms of M in arbitrary, computable ways through the new connections)。
有意思但是没有深入探讨的问题:
- 建立新模型时,怎么避免catastrophic forgetting,不管是训练M还是C,long term地学下去势必会记新忘旧。文中提出在以前的经验里随机抽取一些穿插训练(第6章第5段)。 但是online agent是没有外部存储把以前的经验都存下来的,有的也只有关于以前经验的记忆(压缩以后的经验)。因此这里只能把压缩经验解压缩出来replay,这里是不是有点像一个generator或者是decoder呢?
- Neuron grow和prune。M和C在学习新的经验和task时,可以加入新的neuron也可以删除掉不用的neuron。(第4.2、5.4节)
- 文章简要描述了一个thinking过程,C以某种方式explore,exploit或者ignore M。论文强调了把C和M连起来组成一个大的RNN,C就在理论上能够具有这种能力了,但是具有这种能力的可能性和真正能够学到这一技能还是有差距的。更美好的,把M和C连起来,C能够在抽象层面thinking,如何才能做到?
- 预测网络只是预测t+1时刻的状态,这样达不到层次效果。对action sequence压缩,预测多步动作结果能够建立更好的世界模型。